
En Busca del Modelo Perdido - Parte 8: El Laberinto de XGBoost
Mientras continuamos nuestra odisea en “En Busca del Modelo Perdido”, nos adentramos en un territorio inexplorado en el capítulo ocho: el mundo de XGBoost. Antes de sumergirnos en el laberinto de sus hiperparámetros, es esencial comprender qué es XGBoost y cómo se diferencia de nuestro anterior compañero de viaje, Random Forest.
🌳 XGBoost: Un Nuevo Horizonte en Modelos Basados en Árboles 🌳
XGBoost, que significa eXtreme Gradient Boosting, es una evolución sofisticada de los modelos basados en árboles de decisión. Mientras que Random Forest construye un ‘bosque’ de árboles de decisión independientes para crear predicciones robustas y generalizadas, XGBoost perfecciona esta idea utilizando el enfoque de Boosting. Aquí, cada árbol se construye secuencialmente, aprendiendo y mejorando de los errores del anterior, lo que lo convierte en un solista meticuloso en nuestra orquesta de modelos de Machine Learning.
Ahora, con este entendimiento de XGBoost, nos adentramos en su aspecto más desafiante y crucial: los hiperparámetros.
🌟 XGBoost: Un Nuevo Capítulo en Nuestra Saga 🌟
Recordando nuestro viaje anterior, vimos cómo Random Forest, representando el Bagging, funcionaba como una orquesta sinfónica, donde cada instrumento contribuía a una melodía robusta. Ahora, con XGBoost, nos movemos hacia un enfoque más solista y perfeccionista del Boosting, destacado en el capítulo 7.
import xgboost as xgb
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_absolute_error
# Supongamos que 'X' y 'y' son nuestros datos de características y etiquetas
X = ... # Características del conjunto de datos PAES
y = ... # Puntajes PAES
# Configuramos el modelo XGBoost con hiperparámetros seleccionados
xg_model = xgb.XGBRegressor(
learning_rate=0.1,
n_estimators=350,
gamma=2.5,
min_child_weight=7,
subsample=0.5,
colsample_bytree=0.5,
colsample_bylevel=0.5,
colsample_bynode=0.5,
reg_lambda=5,
max_depth=5,
random_state=42
)
# Validación cruzada para evaluar el modelo
scores = cross_val_score(xg_model, X, y, cv=5, scoring='neg_mean_absolute_error')
mae = -scores.mean()
print("MAE promedio: %f" % (mae))
En este fragmento, aplicamos validación cruzada para evaluar nuestro modelo. A primera vista, podríamos obtener un gráfico que muestra resultados impresionantes, sugiriendo una predicción casi perfecta. Sin embargo, debemos ser cautelosos: ¿es esto realmente una muestra de precisión o hemos caído en la trampa del sobreajuste?
Para hacerlo notar, aquí he aplicado este modelo con algunos de los parámetros dados:
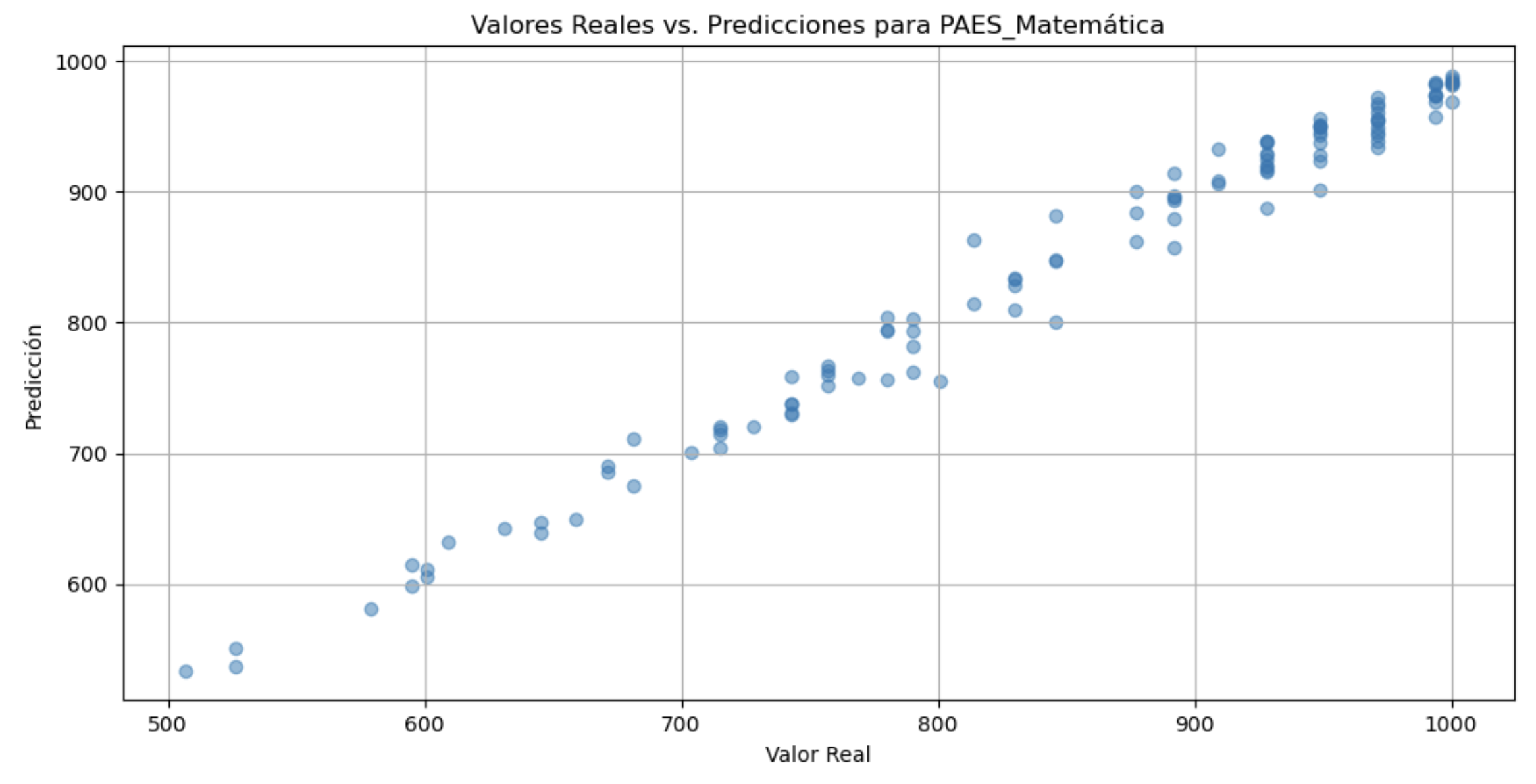
Este gráfico puede parecer prometedor (de hecho llega a ser casi perfecto en su linealidad), pero en realidad, puede ser una ilusión del verdadero rendimiento del modelo, especialmente en datos desconocidos. El modelo se ajusta muy bien a los datos qeu tenemos y a la información que ya es sabida, pero lo más probable es que no se ajuste de ninguna forma a los datos que nos son desconocidos, es decir, no se ajustarán bien para hacer una predicción.
🔍 Navegando por los Hiperparámetros de XGBoost 🔍
Cada hiperparámetro de XGBoost es un artefacto crucial en nuestra aventura, similar a los que Indiana Jones encontraría en sus expediciones. Los exploramos detalladamente, comprendiendo su función y cómo afectan nuestras predicciones:
- Learning Rate (Tasa de Aprendizaje): Controla el paso con el que el modelo se ajusta a los datos. Un paso demasiado grande puede hacer que el modelo se pierda detalles finos.
- N_Estimators (Número de Estimadores): El número de árboles de decisión en el modelo. Más árboles pueden llevar a un mayor riesgo de sobreajuste.
- Gamma: Un parámetro de regularización que ayuda a controlar la complejidad del modelo.
- Min Child Weight: Un umbral para decidir cuándo se debe detener la división de un nodo, afectando la complejidad del modelo.
- Subsample: La fracción de muestras utilizadas para entrenar cada árbol. Un subsample bajo puede llevar a un modelo más robusto.
- Colsample_by_: Estos parámetros controlan la fracción de características consideradas para cada árbol, nivel o división. Una selección más pequeña puede prevenir el sobreajuste.
🚀 El Desafío de XGBoost: Evitando las Trampas del Sobreajuste 🚀
A diferencia de Random Forest, XGBoost puede ser susceptible al sobreajuste. Es como si Indiana Jones enfrentara una serie de espejismos mientras busca un tesoro. Necesitamos ajustar los hiperparámetros cuidadosamente para evitar seguir un mapa engañoso.
📈 Próximo Capítulo: Ajustando el Compás hacia la Predicción Perfecta 📈
En el próximo capítulo, nos enfocaremos en ajustar estos hiperparámetros para encontrar un equilibrio entre la precisión y la capacidad de generalización, evitando las trampas del sobreajuste. Cada paso será crucial en nuestra búsqueda del Santo Grial de la predicción de los resultados de la PAES.
Hasta el próximo cronopunto del Principia 🥚.
DV