

En Busca del Modelo Perdido - Parte 4: Explorando el Random Forest
Bienvenid@s al cuarto capítulo de nuestra serie “En Busca del Modelo Perdido”. En esta entrega, nos enfocaremos en desentrañar los secretos del Random Forest y su aplicación en la predicción de los resultados de la PAES. Si te perdiste el capítulo anterior sobre cómo ChatGPT nos ayudó a dar los primeros pasos en la creación de nuestro modelo predictivo, te invito a leerlo aquí.
🌲🌲 El Bosque de Decisiones: Introducción al Random Forest 🌲🌲
Imagínate un equipo de asesores, cada uno especializado en un área diferente, trabajando juntos para resolver un problema complejo y en donde cada uno con su experiencia vota por el camino a seguir. Esto es similar a lo que hace el Random Forest en el mundo del aprendizaje automático pero con un grado de complejidad por supuesto mucho más amplio.
🌳 Nodos y Ramas: Decisiones Estratégicas 🌳
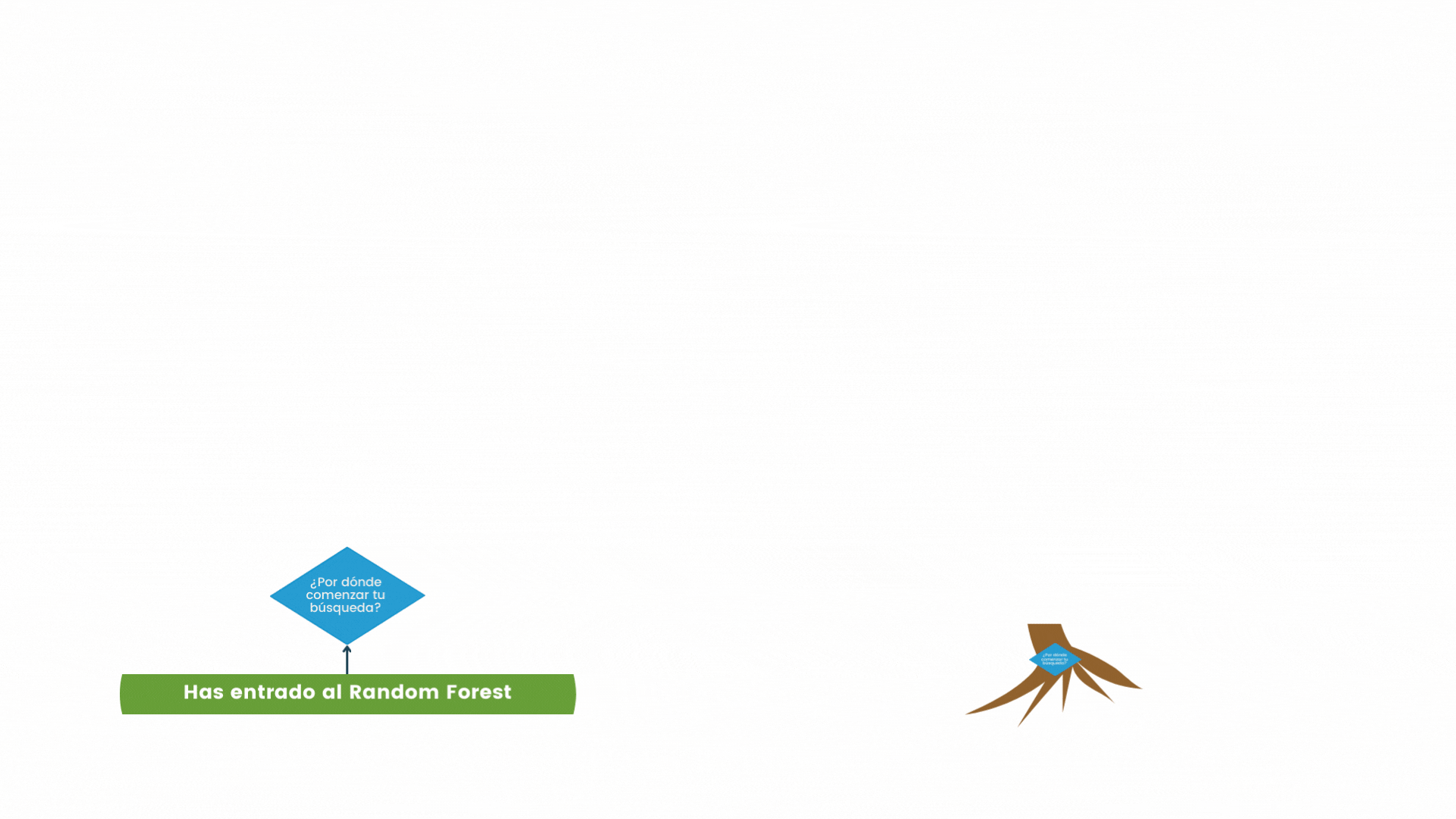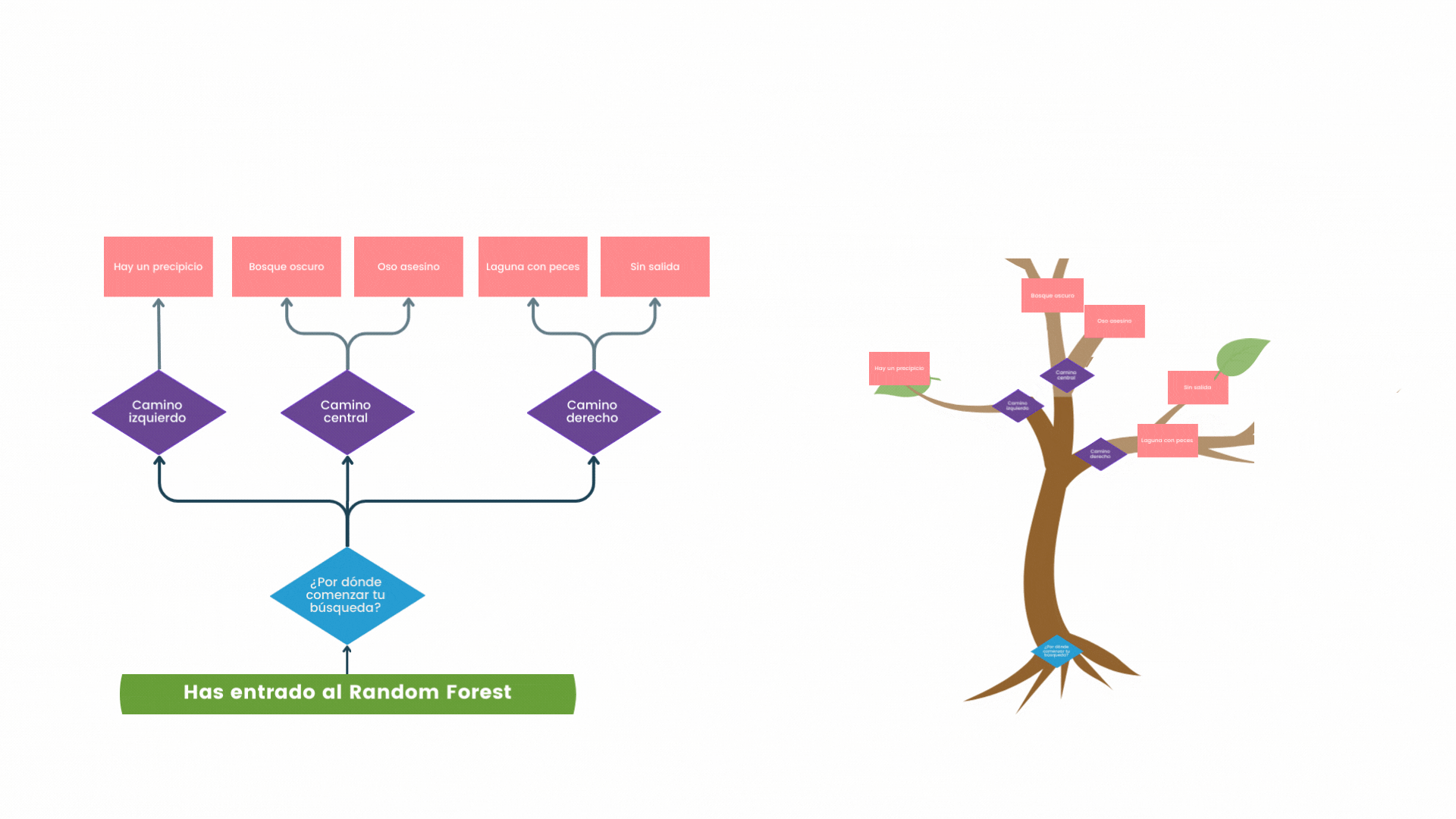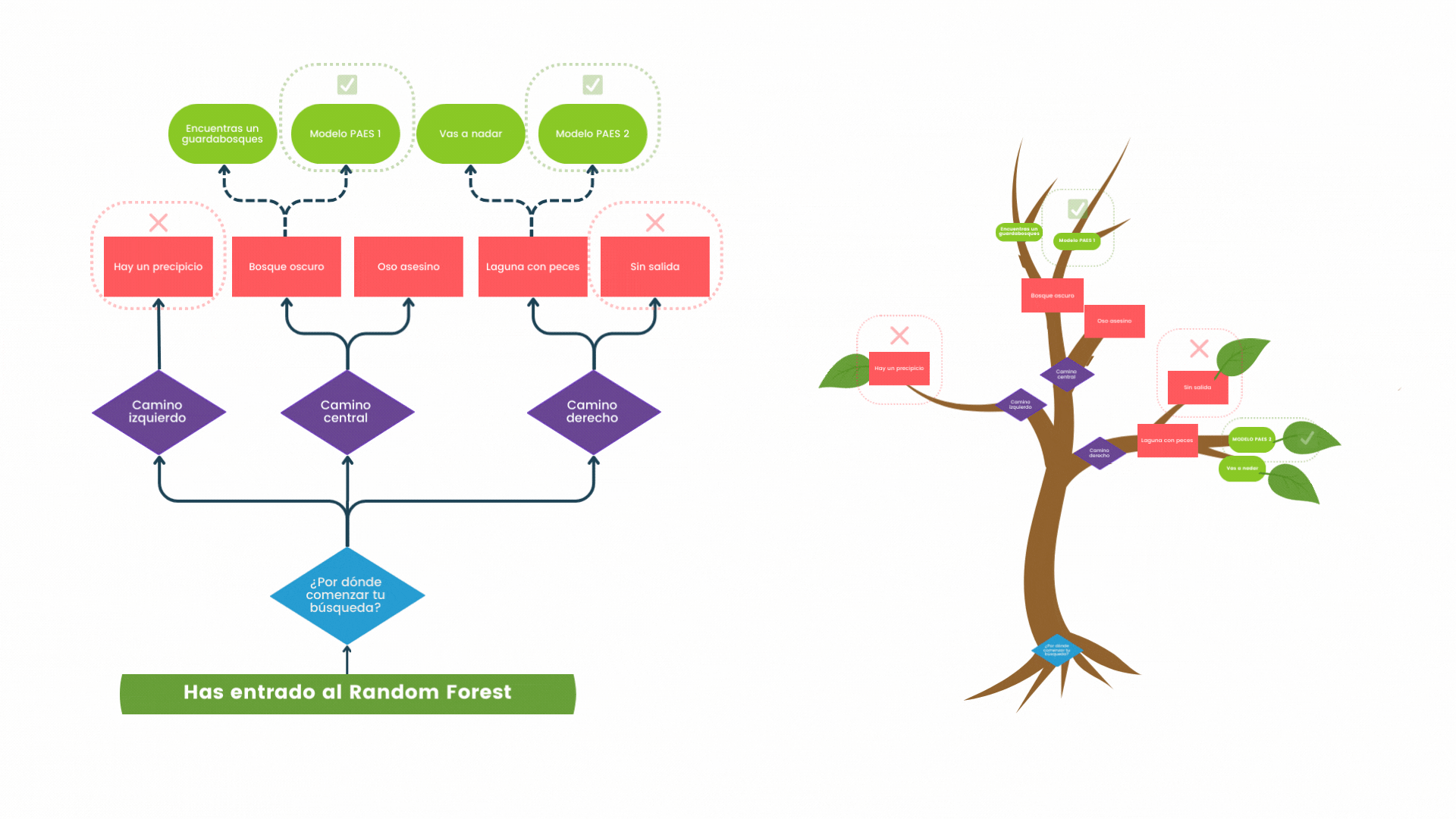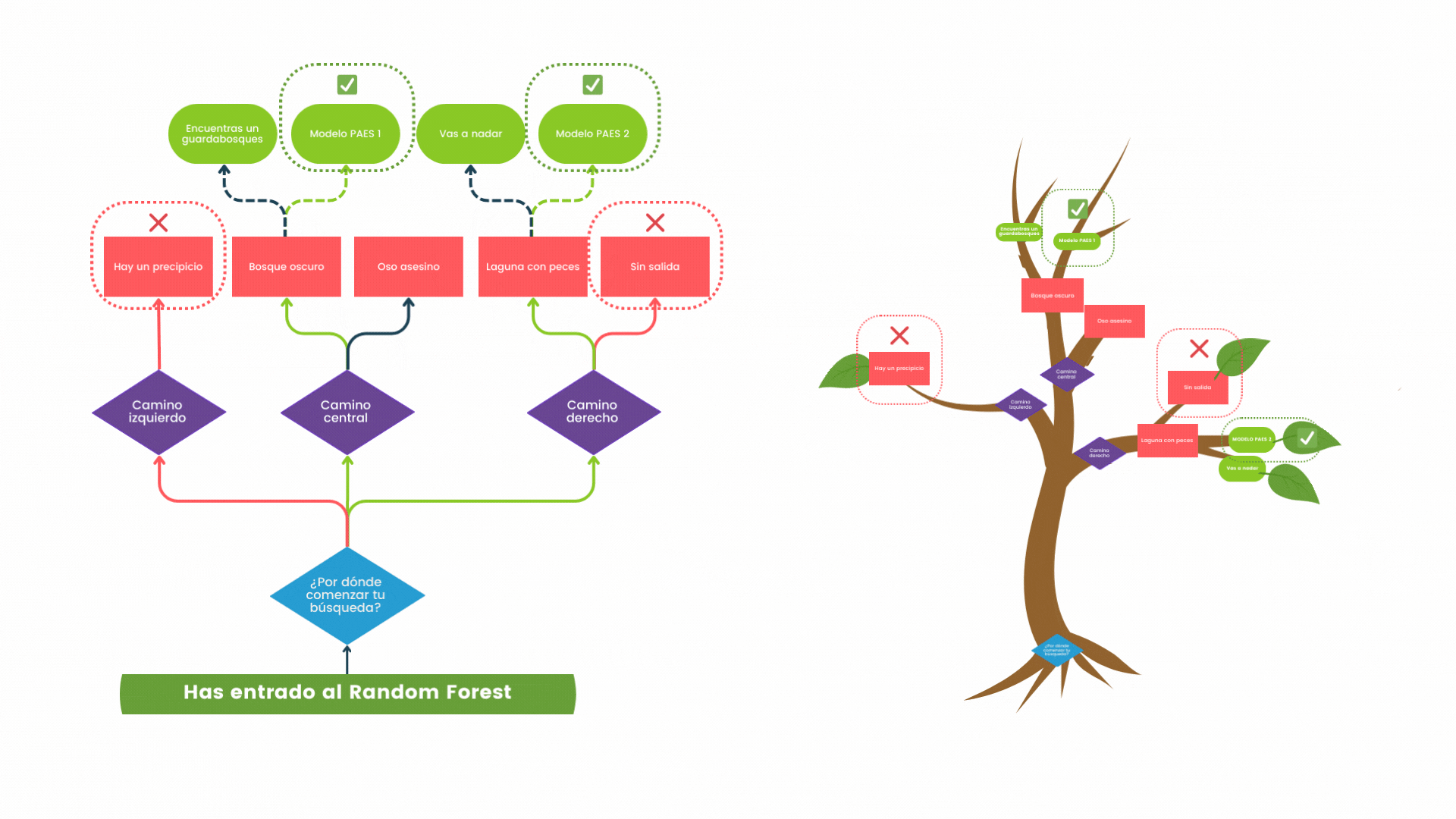
En un árbol de decisión del Random Forest, cada punto de decisión se llama nodo y el camino al que conduce es una rama. Por ejemplo, un director de colegio podría enfrentarse a la pregunta inicial: “¿Cómo influye el clima escolar en el rendimiento académico?”. Aquí se debe tomar una decisión (nodo) y, dependiendo de los datos que se tengan, esta pregunta conduce a diferentes caminos de acción y análisis (rama).
Código de Ejemplo: Creando un Árbol de Decisión
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(X, y) # 'X' son las características del clima escolar, 'y' es el rendimiento académico.
🌿 Poda: Enfocando el Análisis 🌿
La poda es un proceso mediante el cual se eliminan las opciones menos relevantes para hacer el análisis más eficiente (resultados iguales o mejores con los mismos o menos recursos). Por ejemplo, el director podría descartar factores como los cambios menores en el menú del comedor para evaluar el impacto del clima escolar en el rendimiento académico. Esto haría que se centre en los aspectos más influyentes de lo que quiere saber (poda).
Código de Ejemplo: Poda de un Árbol de Decisión
tree = DecisionTreeClassifier(max_depth=3) # Limitando la profundidad del árbol.
tree.fit(X, y)
🌳 Padres e Hijos: Desarrollando Estrategias 🌳
Cada decisión inicial puede conducir a nuevas decisiones subsecuentes. Si el director decide enfocarse en mejorar el clima escolar, la siguiente pregunta podría ser “qué recursos adicionales se necesitarán”, representando así un nuevo nodo (nodo hijo) en la cadena de decisiones.
Código de Ejemplo: Visualización de Nodos en un Árbol de Decisión
import matplotlib.pyplot as plt
from sklearn import tree
plt.figure(figsize=(20,10))
tree.plot_tree(tree.fit(X, y), filled=True)
plt.show()
🌳🌳 Parámetros Clave en Random Forest 🌳🌳
Los parámetros n_estimators y random_state tienen un papel fundamental en el Random Forest. Consultar a diferentes miembros del equipo educativo proporciona una visión más completa del problema, esto es idéntico a cómo más árboles en un Random Forest ofrecen una perspectiva más rica y diversa (n_estimators).
Código de Ejemplo: Random Forest con Diferentes n_estimators
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100)
forest.fit(X, y)
Usar un random_state específico es como asegurar que cada vez que se consulte, se obtengan opiniones consistentes de las mismas personas, lo que es crucial para comparar y entender las tendencias a lo largo del tiempo (random_state). En el caso de que este valor decida no establecerse, será aleatorio, lo que es equivalente a hacer la misma consulta a personas diferentes de tu equipo académico.
Código de Ejemplo: Random Forest con un random_state Específico
forest = RandomForestClassifier(n_estimators=100, random_state=42)
forest.fit(X, y)
🌟🌟 Conclusión: El Poder del Random Forest en la Educación 🌟🌟
El Random Forest, como hemos visto, es una herramienta valiosa para predecir resultados educativos como los de la PAES. Su habilidad para adaptarse a variados patrones de datos y su estructura compuesta por múltiples árboles de decisión, lo hacen ideal para entender y mejorar el rendimiento estudiantil.
Este método nos permite no solo predecir con mayor precisión, sino también comprender mejor los diversos factores que influyen en el éxito académico. Su uso en la educación abre caminos para intervenciones más informadas y efectivas, marcando un avance significativo en cómo abordamos los desafíos educativos.
Espero estos cnceptos básicos hayan ayudado a mejorar tu idea de lo que hará el código en los siguietnes capítulos. Continuemos explorando las posibilidades que nos brinda el aprendizaje automático o Machine Learning para enriquecer el mundo de la educación.
A continuación te dejo también un pequeño GIF que engloba buena parte de la comprensión de lo que sería un árbol de decisión. Espero pueda reforzar tu entendimiento del nuevo concepto.
Hasta el próximo cronopunto del Principia 🥚.
DV