

En Busca del Modelo Perdido - Parte 3: El Random Forest + ChatGPT
Hemos llegado a una encrucijada y el camino tiende a hacerse más complejo. La información del bibliotecario no traía consigo las decisiones que tendríamos que tomar en el camino, por lo que aquí debemos echar mano a nuestra experiencia, o en caso de no tenerla, a nuestro espíritu de aventura.
Hoy en día tenemos herramientas que pueden darnos una solución bastante robusta sin tener demasiados conocimientos de programación. Una de ellas es ChatGPT que, además de ser gratuita y tremendamente versátil, creo que a estas alturas ya no hay que salir de casa sin ella … ¿o él?
Aquí aparece una complicación. Si no tenemos grandes conocimientos de programación ¿cómo podríamos saber que lo que estamos generando con ChatGPT responde a nuestras necesidades? Por supuesto, esta pregunta nos hace dudar si tomar un curso de programación - y hacer el trabajo con nuestras propias manos - o bien idear alguna alternativa que me permita entender lo que saldrá de ese “bicho”.
El dilema es evidente, ¿ChatGPT o Yo? … en este primer trabajo quizás la respuesta más cercana a la decisión será “ambos”.
🔮 Visita al oráculo … ChatGPT 🤖
En nuestro primer capítulo vimos la manera de trabajar un dataset que contenía la información para lograr nuestra misión… lograr un modelo predictivo de la PAES para el 2024. El archivo que contendría los datos sería en CSV y solo las columnas distintas de ‘ID’, ‘Curso’, ‘Nombre’ y ‘PAES’ serían las que construirían el modelo. Con esto en mente y el nombre del archivo, vamos a preguntar a ChatGPT respecto de un modelo de random forest que literalmente nos permitiera hacer una predicción de los resultados PAES - supongo que en pedir no hay engaño -.
Así que nos armamos de valor, vamos al lugar del oráculo y “pronunciamos las palabras mágicas”:
“Oh gran ChatGPT, usa un archivo de CSV cuyo nombre es PAES_training_set_2022_Complete - PAES_training_set_2022 - Matemáticas.csv y entrega el código en python para poder predecir los resultados de la columna llamada “PAES” descartando las columnas llamadas ‘ID’, ‘Curso’ y ‘Nombre’ para entrenar el modelo. Usa todas las otras aplicando el método de random forest y grafica los resultados de valores reales vs valores predichos por el modelo”
La emoción comienza a llegar a nuestro ser y tras esperar un par de segundos aparece el siguiente mensaje:
Lamentablemente, no puedo acceder ni utilizar archivos específicos, como el archivo CSV que mencionas, ya que mi capacidad de interactuar con el entorno es limitada y mi conocimiento está basado en datos que se detienen en enero de 2022. Sin embargo, puedo proporcionarte un código genérico en Python que puedes utilizar como punto de partida para realizar la tarea que mencionaste. Solo necesitas asegurarte de cargar tu archivo CSV con los datos adecuados. Asegúrate de que tengas la biblioteca Scikit-Learn instalada para usar el modelo Random Forest. Puedes instalarlo usando pip install scikit-learn.
Respuesta inicial de ChatGPT
Asombrad@s por el resultado, decidimos simplemente copiar y pegar este código en nuestro cuaderno de Jupyter dispuesto para trabajar (hablaremos de esto en otro post en caso de que te sea muy ajeno). Al hacerlo llega nuestra primer obstáculo.
🏗️ Construyendo la solución ⚒️
El output del código entregado por ChatGPT fue un error que se muestra en la imagen a continuación:

Claramente el oráculo no es infalible, ya que no conoce todo el contexto de nuestros datos. Así que copiamos y pegamos este mensaje de error en él para que tenga mayor información respecto del error. Lo que nos entregó fue la siguiente respuesta:
El error que estás viendo se debe a la presencia de valores faltantes (NaN) en tus datos. Antes de entrenar un modelo de Random Forest, debes ocuparte de manejar estos valores faltantes. Aquí hay una versión modificada del código que incluye la imputación de valores faltantes utilizando SimpleImputer de scikit-learn:
ChatGPT tras error 1
Tras borrar el código anterior e incluir el nuevo en nuestro cuaderno Jupyter nos topamos otra vez con otro error 😔.

“¡Que cosa más desesperante esta!” dirán algun@s, pero lo cierto es que el proceso de construcción de una buena respuesta con ChatGPT puede tomar tanto como construir nosotr@s mism@s nuestro código desde cero si no damos los suficientes detalles al “oráculo”. De hecho, puede incluso ocurrir que la respuesta no llegue hasta después de muchas iteraciones o quizás correcciones que un@ mism@ tendrá que reconocer.
Tras ingresar nuevamente el error a ChatGPT, nos entrega otra respuesta más:
Si estás obteniendo un error que indica que “Input y contains NaN,” significa que tus etiquetas objetivo (en este caso, la columna ‘PAES’) también contienen valores faltantes (NaN). Debes manejar los valores faltantes en las etiquetas objetivo antes de entrenar un modelo. Aquí hay una versión modificada del código que aborda este problema utilizando la imputación de valores faltantes en las etiquetas objetivo:
ChatGPT tras error 2
🏆 Nuestro Primer Logro 🏆
¡El código resultó! Tras dos intentos fallidos finalmente logramos ver un “output” que nos muestra un resultado interesantísimo. Además, no solo nos entregó un gráfico como le solicitamos, sino que una estimación del error en la predicción que se llamó “Error Cuadrado Medio” o “Error Cuadrático Medio” (ECM). Si no estas muy familiarizad@ con la estadística, basta con saber que esto nos da una estimación de qué tan bien se ajusta este modelo con los datos.
De hecho, si calculamos la raíz cuadrada de esta valor (que aquí nos dio 1409.76) tendremos una idea más clara de cómo se ajusta el modelo ya que este valor tendrá las unidades de la variable que estamos modelando. La raíz del ECM o RMSE por sus siglas en inglés nos dio en este caso 37,54 que representaría las desviaciones que tendría este modelo predictivo con la realidad. Es decir, nuestra predicción de los resultados PAES en la prueba de matemática no serían mucho más que 37,54 puntos … que en este caso representan unas 2 a 3 preguntas como máximo.
¿Nada mal para alguien que solo está partiendo no?
El gráfico expulsado fue este:
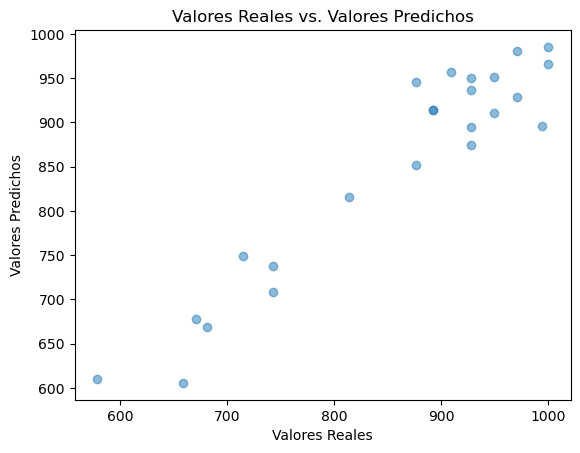
… y como podemos ver, se ajusta realmente bastante bien a los valores que teníamos en nuestros datos.
Todo parece muy bien hasta ahora … aunque hay algo que no se siente “bien”.
🤔 Algo Anda Mal … 🤔
Nuestra labor como investigadoræs es cuestionar, y cuestionar fuertemente. Por esta razón creo que es importante resaltar algunas preguntas que nacen si echas cuenta de lo que hemos hecho para obtener nuestro modelo:
- El primer error se obtuvo porque habían datos vacíos en mi dataset ¿Qué hace la función SimpleImputer que resolvió ese problema?
- ¿Qué debo hacer con los valores que son estan vacíos de mi dataset? ¿Debería eliminarlos? ¿Eliminar una fila entera? Reemplazar solo el dato? ¿Y con qué valor?
- Si pierdo datos o los reconstruyo de alguna manera, ¿Pierdo precisión en mi modelo predictivo? ¿Agrego algún tipo de ruido?
- ¿Qué son las variables n_estimators y random_state al momento de aplicar el código de random forest? ¿y por qué tienen los valores de 100 y 42? ¿Son correctos para mi situación?
La respuesta a estas preguntas solo depende de lo bien que entiendas el problema y a qué decisiones debes tomar para sortear/parchar/eliminar estas dificultades. El mundo parece no ser perfecto en estas líneas de trabajo, por ende una solución demasiado perfecta o sencilla debe parecernos contraproducente … o a lo menos cuestionable.
Tras averiguar lo que hace la función SimpleImputer, se puede corroborar que es una función que inserta valores a nuestro dataset para que pueda llenar los espacios que se encuentran vacíos. Esto no parece adecuado para los fines que buscamos, ya que al ser un modelo predictivo no deberíamos introducir por nuestra cuenta valores que pueden afectar el modelo.
En un segundo aspecto, si hay valores de la columna PAES que estan vacíos, entonces no es posible usar los otros valores para estimar una predicción, ya que no sabemos el resultado al cual deberíamos llegar. Por ende esa fila completa debería desaparecer de nuestro dataset.
Considerando estos razonamientos, parece justo decir que para obtener el modelo que mejor se adecúe y que no tenga “ruido” por los valores que no estaban en la base original, entonces debemos borrar todas las filas que tengan algún dato faltante.
🌳 La Última Pregunta 🌳
Pedimos a ChatGPT que considere borrar todas las filas que tengan valores vacíos o nulos. El código final fue este:
Como verás, aquí no nos preocuparemos de momento por las variables n_estimators y random_state ya que es un espacio completo para otro artículo. Pero claramente es un problema que tendremos que abordar.
El output del código fue el siguiente:
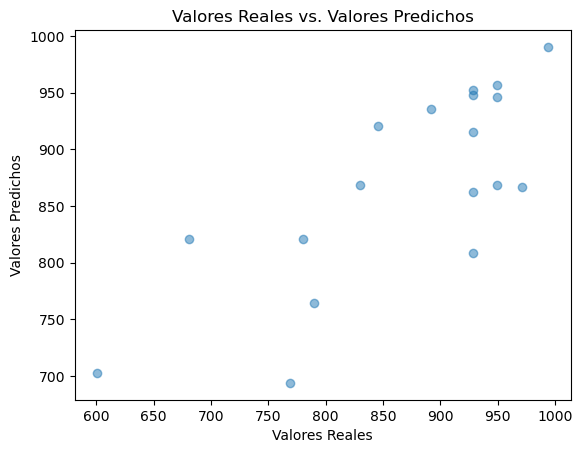
El resultado es un gráfico que tiene muchos menos puntos y que presenta claramente una precisión menor respecto del anterior (RMSE = 68,42)… aunque creo que se siente “más razonable”. Corregimos un problema importante como lo eran los datos introducidos “manualmente”, lo que agrega una cuota de tranquilidad a nuestro trabajo ya que nos acercamos un poco más a la realidad mientras más conocemos lo que estamos haciendo.
Solo nos resta una cosa más… entender el código y los parámetros que lo definen para ver si es posible mejorar la precisión en las predicciones y afinar esto lo mejor posible. Pero hasta entonces, creo que nos merecemos un descanso… ha sido un largo camino por el Random Forest.
Hasta el próximo cronopunto del Principia 🥚.
DV



