

En Busca del Modelo Perdido - Parte 1: Exploración
Partir en el análisis de datos puede ser un camino complejo para quienes no manejan demasiado la programación. De hecho yo mismo no me considero un experto, pero como he mencionado en publicaciones anteriores, mi objetivo es ser un aprendanzante experimentado, así que quisiera aprender enseñando.
En este primer artículo buscaré mostrar las primeras etapas de exploración del análisis de datos, así que compartiré parte del código que estoy usando para descubrir un posible modelo que prediga los resultados de una prueba de acceso universitario con los datos de un colegio.
Análisis de Datos Exploratorio (ADE)
Al partir el viaje necesitamos explorar. Tal como Indiana Jones 🤠 en cada una de sus aventuras, el objetivo inicial - cuando ya has entendido las necesidades y problemas del lugar donde estas inmers@ - es entender el conjunto de datos que tienes a disposición.
El EDA - o Exploratory Data Analysis (EDA) en inglés - es un proceso en el cual te dedicas a entender tu conjunto de datos para luego comenzar su manipulación. Puedes considerar el punto de vista de las tablas como de los gráficos, pero nunca olvides que la idea fundamental es familiarizarte con la naturaleza … de los datos.
En esta misión utilizaremos una base de datos que se encuentra en un archivo CSV - “comma separated values” o “valores separados por coma” - y lo leeremos con las funciones básicas de Python.
🌿🐒🦟 Entrando en la Jungla de Datos 🐍🐊🌿
Lo primero es definir nuestras herramientas de trabajo, y en python esto quiere decir referirse a las liberías. El código a continuación permite leer el archivo CSV que mencionamos anteriormente.
1
2
3
4
5
6
7
8
9
10
11
# Declaramos librerías necesarias
# Necesitaremos Numpy para hacer procesamientos matemáticos y Pandas para manipular el dataset en CSV
import numpy as np
import pandas as pd
# Definimos la ruta donde se encuentra el dataset
csv_filename = "ruta_al_dataset_para_armar_el_modelo.csv"
# Usamos el comando read_csv para leer el archivo con los datos desde la ruta anterior
data = pd.read_csv(csv_filename)
Observación: No olvides que el archivo CSV tiene que estar en la misma carpeta donde estas corriendo el código o bien escribir correctamente la ruta a la carpeta que contiene el dataset (set de datos).
Las propiedades del entorno
Hasta aquí nos posicionamos ya en el lugar donde queremos trabajar, ahora hay que dar una mirada. Para eso utilizamos el comando “info()” para así tener una idea inicial de qué es lo que contiene el dataset.
1
2
# Usamos el comando read_csv para leer el archivo con los datos desde la ruta anterior
data.info()
El output después de aplicar este comando es algo así:
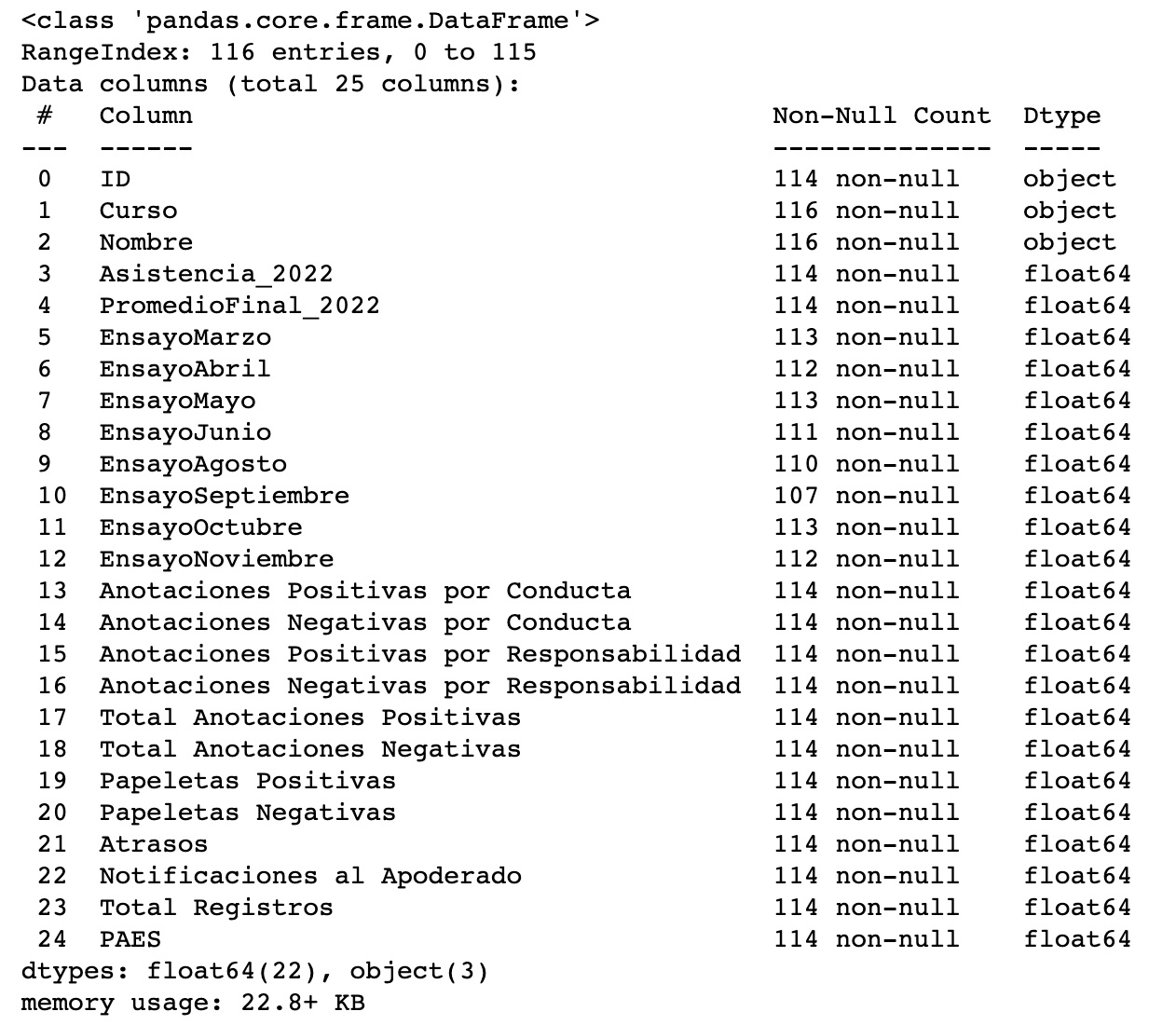
Aquí podrás ver los nombres de los encabezados de cada una de las columnas, el conteo de los valores que no son noles (Non-Null Count) y la naturaleza de los datos encontrados (Dtype).
Con esto ya hay una primera mirada pero un elemento clave dentro del análisis de datos es saber cuántos de estos datos son nulos para así tener una mejor idea de con cuántos datos contarás al final para hacer tus modelos. Para esto puedes usar el siguiente comando:
1
(data.isnull().sum()/(len(data)))*100
El output de este comando es el siguiente:
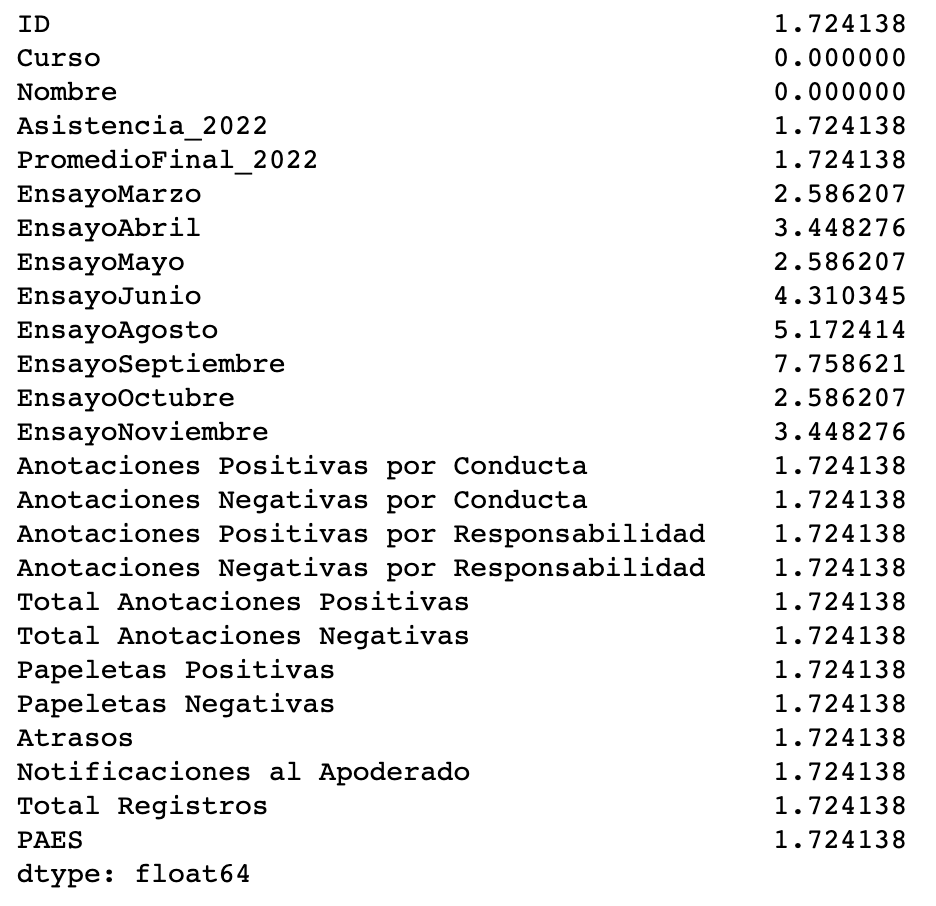
Un detalle de los elementos de esta instrucción es el siguiente:
- El comando .isnull() identifica los valores que son nulos dentro del dataset.
- El comando .sum() hará la suma de estos datos por culumna
- El comando .len(data) hará el conteo de los elementos del dataset (data) incluyendo los valores no nulos
- Finalmente el comando *100 está multiplicando el resultado de (data.isnull().sum()/(len(data))) por 100 para así dejar el output como si fuera un porcentaje
Y esto ha sido el inicio de nuestra travesía buscando modelos de predicción. Nada mal para ser un@s iniciad@s en el tema 🤠.
Hasta el próximo cronopunto del Principia 🥚.
DV
Anexos
A continuación tienes el código completo analizado en esta publicación.



